When a company relies on cloud services, SRE, DevOps, performance engineering, and finance often clash over optimizing cloud bills and incident reports. The root cause of the problem is the lack of resources available to address the issues. Most tools can clearly identify what’s wrong, but very few reliably offer a solution on how to fix it across hundreds of interacting configuration parameters.red
This is where Akamas comes into play. Akamas was built to close that gap with a deterministic, reinforcement-learning-driven optimization engine and deep domain models for the tech stack (Kubernetes, JVM/.NET/Node.js runtimes, databases, OS, and more).
Software Plaza conducted a webinar with the Akamas team, including CEO Luca Forni and CTO Stefano Doni, to explore Akamas' product offering, which features AI-driven optimisation. This blog post explores seven methods for capturing savings and reliability without compromising one for the other.
1. Start where waste hides: right-size requests & limits and the runtime inside the pod
Most Kubernetes cost waste lives in plain sight: CPU and memory requests/limits set “for safety,” then forgotten. But there’s a second, often ignored layer: the application runtime (e.g., JVM) running inside the container. You can slash pod memory limits, but if the JVM heap is still oversized, you'll likely experience throttling or OOMs later.
What AI does differently: Akamas correlates workload metrics with runtime internals (heap size/usage, GC behavior) and issues paired recommendations: shrink the pod and the JVM heap (or tune GC), or increase limits and reduce runtime waste to avoid OOM risk. This “twin-tuning” yields meaningful savings without reliability regressions.
Outcome: Significant reductions in CPU cores and GBs of RAM per workload, and fewer GC pauses and throttling events.
2. Tune autoscaling with your SLOs, not just averages
Horizontal Pod Autoscaler defaults are deceptively simple but can whipsaw your SLOs: scale too slowly during spikes and you breach latency targets; scale too aggressively and you burn money on headroom you don’t use.
What AI does differently: By searching parameter combinations (metrics, thresholds, stabilization windows) against your SLOs, Akamas finds autoscaling settings that hit reliability targets while minimizing over-provisioning. It treats optimization as a multi-objective problem, cost, performance, and reliability together, so you don’t fix one dimension and break another.
Outcome: Faster recovery from traffic peaks with fewer replicas overall and better SLO adherence.
3) Make optimization continuous, not a one-off project
Code changes weekly, dependencies update, traffic patterns shift, and production realities never match staging forecasts. Optimization is not a ticket; it’s an operating motion.
What to implement:
- A lightweight continuous optimization loop: observe → analyze → recommend/auto-apply → verify → roll forward/rollback.
- Run it on a cadence (e.g., weekly) or triggered by events (new release, significant cost drift, reliability regressions).
- Keep humans-in-the-loop where needed, then move proven playbooks to safe automation.
Outcome: Optimization keeps pace with product change, eliminating the need for “big bang” tuning followed by drift back to waste.
4) Consolidate pre-prod and prod learnings into one optimization brain
Pre-production stress tests and capacity planning uncover headroom and failure modes; production observability reveals reality. These streams usually live in silos.
What AI does differently: Akamas ingests both data and insights. It can drive stress tests using your existing tools, learn the response surface of your stack (how latency/cost react to setting changes), and then confirm/adjust in production using telemetry. The result is a closed loop that continuously refines configurations as your system evolves.
Outcome: Faster time to safe settings, fewer surprises in prod, and higher confidence when automating changes.
5) Use full-stack mechanical sympathy, not single-layer tweaks
Kubernetes node pools, cluster autoscaler, CNI, container limits, JVM/CLR/Node, database caches, Linux kernel params, each have hundreds of knobs that interact in non-obvious ways. Tweaking one in isolation often moves the bottleneck.
What AI does differently: Treats the environment like an F1 car, every part tuned to work in harmony. The search space is massive (billions of combinations), but reinforcement learning guided by domain knowledge can quickly converge on balanced configurations across layers.
Outcome: Higher performance at lower cost with fewer regressions, because you optimized the system, not a single dashboard chart.
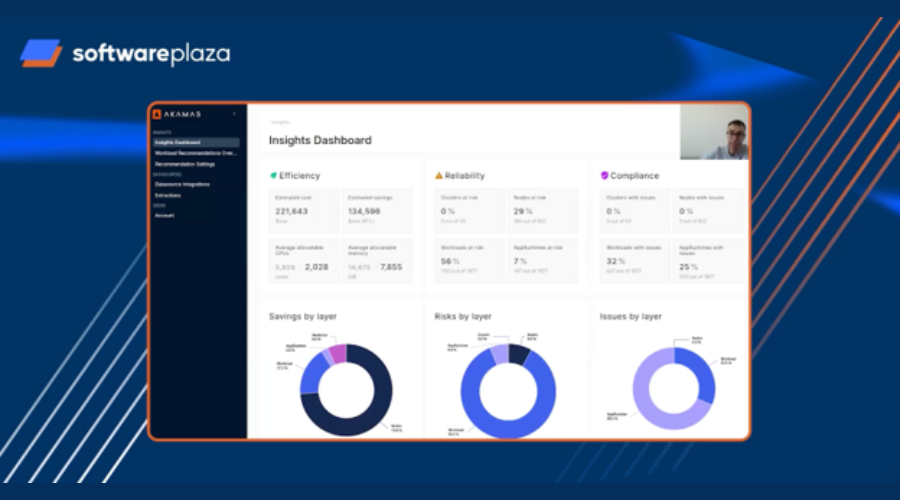
6) Adopt agentless insight first, then automate
Security and platform teams rightly resist “one more agent.” Akamas’ new Insight module for Kubernetes pulls from your existing observability backend (e.g., Datadog) to surface:
- Estimated cost and savings potential
- Reliability risks (e.g., missing requests/limits, throttling, OOM risk)
- Compliance with platform best practices
- The biggest per-workload optimization opportunities
From there, you can apply click-ready kubectl patches and runtime flags manually, prove the benefits, and only then enable automation for the safe playbooks.
Outcome: Zero-friction onboarding and early wins in hours/days, not weeks.
7) Formalize Optimization Governance across teams
Even with perfect recommendations, changes die in committee if no one “owns” optimization. Create a light but explicit governance model:
- Roles: Performance Engineering (methodology), SRE/Platform (guardrails & rollout), Dev Teams (runtime acceptance), FinOps (cost guardrails).
- Policies: Where automation is allowed, rollback criteria, SLOs that bound optimization, and change windows.
- KPIs: $/request, latency at p95, error budget burn, incident rate, and change failure rate.
Outcome: Recommendations become changes, changes become savings, and savings persist.
What results are typical?
While the results depend on an individual company’s baseline and culture, Akamas has witnessed:
- Up to 90% cloud cost reduction on targeted environments in approximately two weeks when right-sizing and runtime tuning were combined
- A 13% web performance improvement on a high-volume e-commerce microservice that translated to ~$800,000/year more revenue, delivered in days, not months.
The pattern: blended goals (cost + reliability + performance), quick wins via agentless insight, then compounding gains as you expand scope and automate.
Why AI (this kind) succeeds where general AI doesn’t
LLMs are transformative, but they’re not designed for multi-objective, high-dimensional configuration search. Akamas’ approach combines reinforcement-learning optimization with deep, technology-specific knowledge (e.g., JVM ergonomics, Kubernetes autoscaling dynamics). That’s why it can discover non-intuitive wins (e.g., reducing heap to improve GC and latency) while keeping the whole system stable.
Key takeaways
- Treat optimization as a system problem: Tune pods and runtimes together, guided by SLOs
- Make it continuous: Tie optimization to releases and drift, not just quarterly cost reviews
- Start agentless: Leverage your existing telemetry to identify quick wins and establish trust
- Institutionalize: A light governance model converts recommendations into durable savings
- Aim for “and,” not “or”: The goal is savings, reliability, and performance, simultaneously
If you’ve already invested in observability, stress testing, and FinOps, you’re halfway there. AI-driven optimization with Akamas is the missing connective tissue that turns all that signal into actionable, safe, continuous improvements, and it pays back fast.
This blog is based on a webinar by Software Plaza. You can watch the full video here.




